Deep Learning evolution
History of Deep learning
▶️ Deep Learning History and Recent Timeline
1998 Lenet
Back in 1998 Yann Lecun was using convolutional neural networks to recognize handwritten digits.

Neural networks were smalls and datasets were also small at that time.
2012 Imagenet
On 2012 AlexNet won the Imagenet challenge. This is the start of the modern deep learning era where 3 factors were combined:
- Big datasets
- GPU compute power
- Algorithmic advances
2019 GPT-2
On 2017 the paper "Attention is all you need" was published. This paper introduced the Transformer architecture which is the basis of the modern natural language models. On 2019 OpenAI released GPT-2 which is a 1.5 billion parameters model. This model was trained on 8 million web pages.
One year later GPT-3 was released which is a 175 billion parameters model. This model was only accessible through an API due to its enormous size.
2022 Dalle-2 and Stable diffusion
2022 was the year of the big breakthroughs in the field of generative models. Dalle-2 was released by OpenAI and Stable diffusion was open sourced months later by Stability AI. These models can generate high quality image from text descriptions. Thus they combine language and vision.

Trends in Deep Learning
Datasets and models are growing exponentially.
Trends in datasets
Epoch AI Trends in Training Dataset Sizes
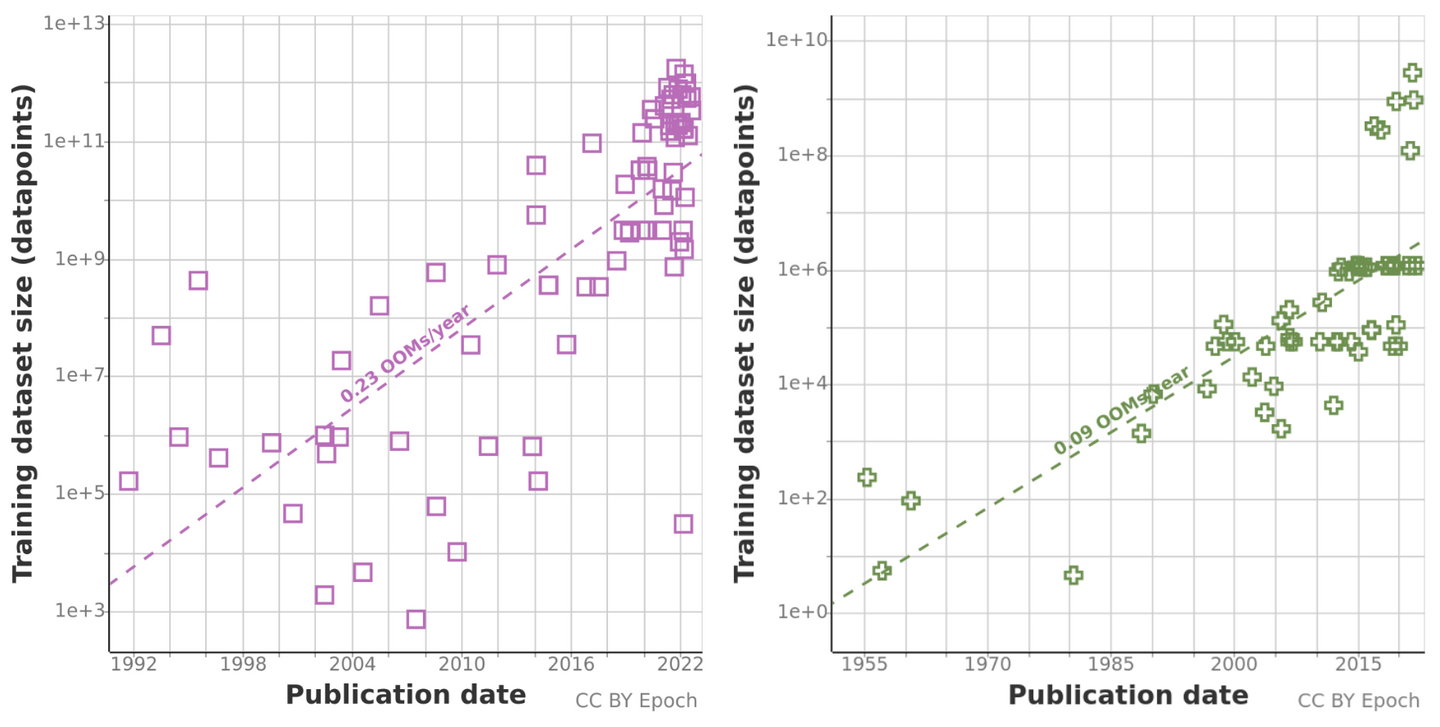
The plots show an exponential growth in the size of the datasets used to train deep learning models.
Trends in model size
Epoch AI Trends in Model Sizes
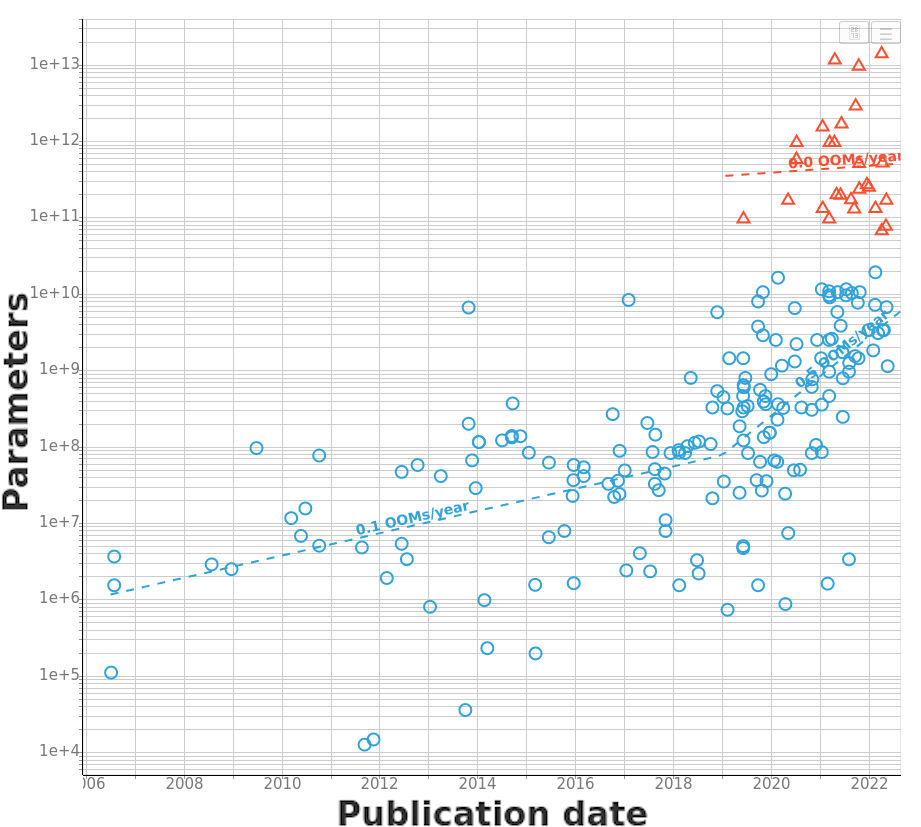
The model size of notable Machine Learning systems has grown ten times faster than before since 2018. After 2020 growth has not been entirely continuous: there was a jump of one order of magnitude which persists until today. This is relevant for forecasting model size and thus AI capabilities.
We can see that the model size also grows exponentially.
The future of Deep Learning
Clearly there is a trend towards bigger and bigger models and datasets. However at the same time this year 2022 we have seen that a model of just 2 GB can generate high quality images from text.
The combination of vision and language has enabled unprecedented levels of generalization. Although the generalization problem is not solved yet this recipe of using a big multimodal text dataset seems to be a promising path to follow.